本文将展示MLAgents的3DBalls示例,并记录将其重构成DOTS并尝试验证DOTS训练AI的可行性。
3DBall运行效果
在terminal启用名为mlagents的环境env,配置好环境,输入命令mlagents-learn --force config/ppo/3DBall.yaml --run-id=first3DBallRun,根据配置环境启动python的训练服务端,然后打开unity提供的demo开始训练。
期望效果
使用更高级的Havok替代传统的PhysX,提供更高效更真实的物理反馈。在DOTS端连接Agents,提供更快的运行速度。
Split Tasks
- 确认原本Mono框架下运行的效率。
- 确认Time.Scale是否能影响到DOTS的subScene。
- 尝试使用PhysicsStep来控制subScene的物理。
- 联通Agents和DOTS。
- 确认DOTS框架下运行的效率。
Tasks
Mono框架下的效率
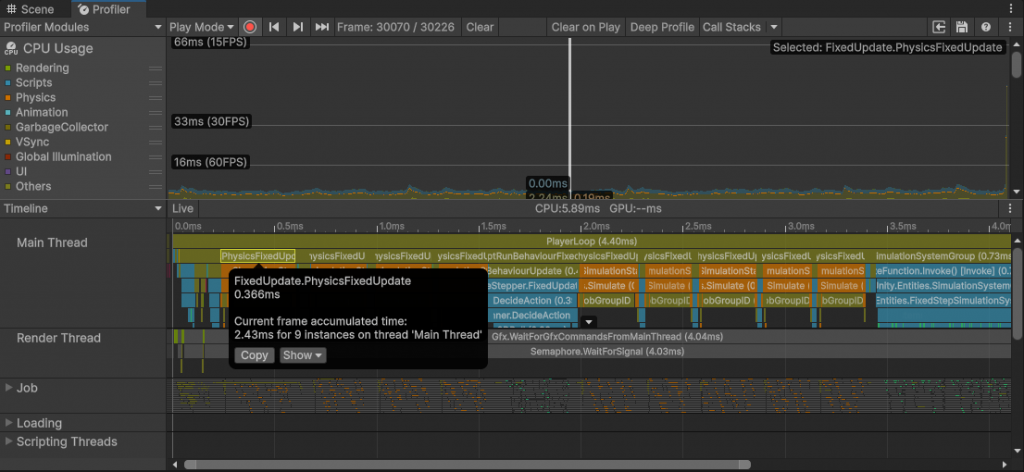
Scene内添加摄像头会导致一帧超过30ms,其中大部分时间在进行RenderLoop。关掉摄像头不进行其他修改会导致一帧只有2-3ms,其中空闲时间超过一半,无法看出Mono框架下的运行效率。简单创建个脚本将Time.scale设置成30,得出上图结果。其中一帧5.89ms,PlayerLoop4.40ms,执行了9次FixedUpdate。
Simple Timescale Test for DOTS
在DOTS端简单做一个弹力球,用同样的脚本更改Timescale。如图所示,Mono框架下修改Time.scale能影响DOTS。在profiler内也可见得。
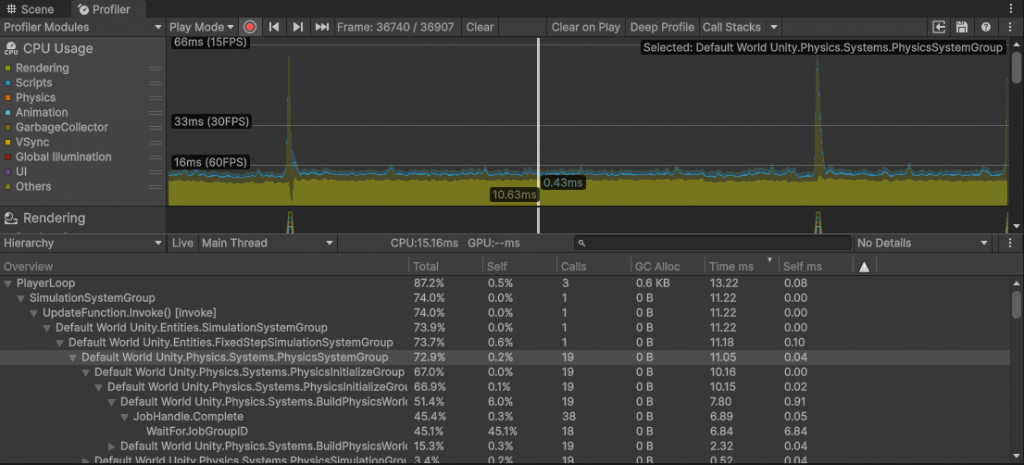
DOTS内FixedStepSimulationSystemGroup中的system类似MonoBehaviour的FixedUpdate。在这个小球DEMO中(摄像头启用),一帧15.16ms内执行了19次FixedStepSimulationSystemGroup。
手动控制物理运行(physicsStep)
手动进行SimulationStep可更好的控制Agent收集observation、执行action的流程,且能更近一步释放cpu的算力。
显得上一步更改TimeScale的操作无意义了
split tasks
该部分可进一步分为几部分:
- 了解整个物理系统的workflow。
- 停止原有的simulation。
- 手动进行step操作。
查看system窗口参阅对应的代码,可发现,PhysicsSystemGroup内先执行PhysicsSimulationPickerSystem,查看SimulationType是否发生更改,启用、关闭对应的system。在subSystem内通过PhysicsStep组件,已将SimulationType设置为Havok。
若在运行时将其改为SimulationType.NoPhysics,PhysicsSimulationPickerSystem将关闭Havok使用的system,启用名为DummySimulationSystem的system。
手动进行SimulationStep有两种方式:
- 及时更改SimulationType。
- 模仿官方示例重造一遍轮子。
为开发考虑采用第一种方式,节省很多精力。
联通Agents和DOTS
前一个部分有个小缺陷:物理的运算是即时的,并且按固定时间间隔运行。这会造成agent已经更改action,却要等待几帧来接收运算结果(a)。
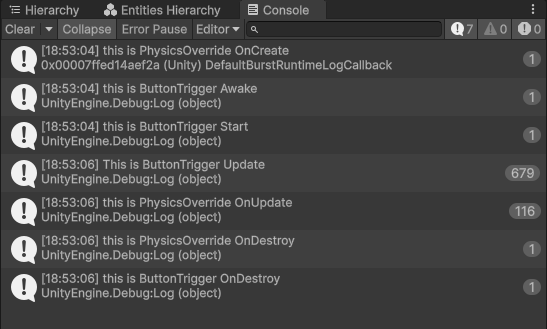
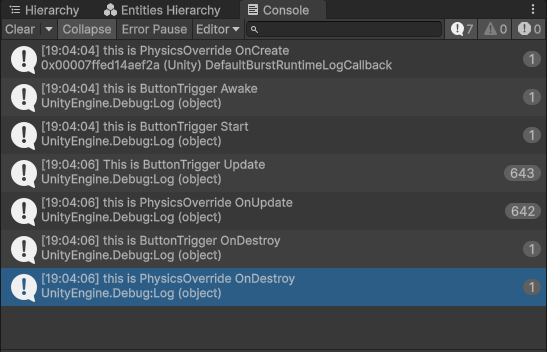
这是因为system运行在FixedStepSimulationSystemGroup内,将其注释后物理与Unity同时运行。
另一个问题是Agent运行的时序问题。
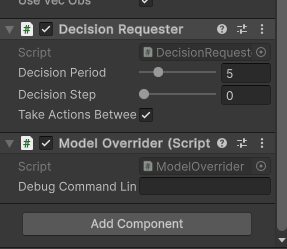
通过在agent脚本内加入对应的debug代码,可看到OnActionReceived、CollectObservations和FixedUpdate发生的次数(c)。FixedUpdate的次数与OnActionReceived次数相同。其中OnActionReceived与CollectObservations的比值大致为5,这是因为在Agent中设置DecisionPeriod(d),间隔5次计算一次输入。实际实现是间隔五次,输入actions不变,输出observation改变actions。
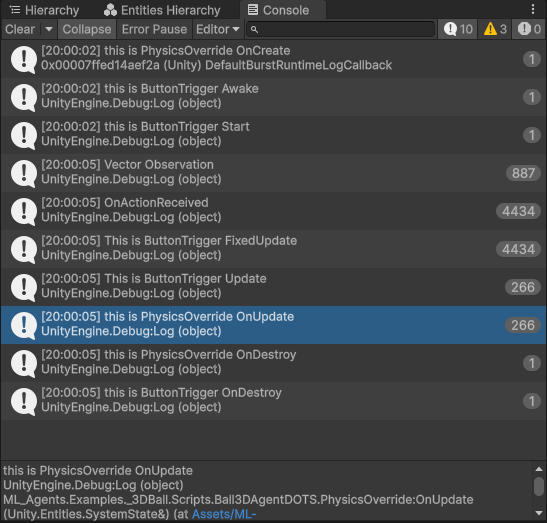
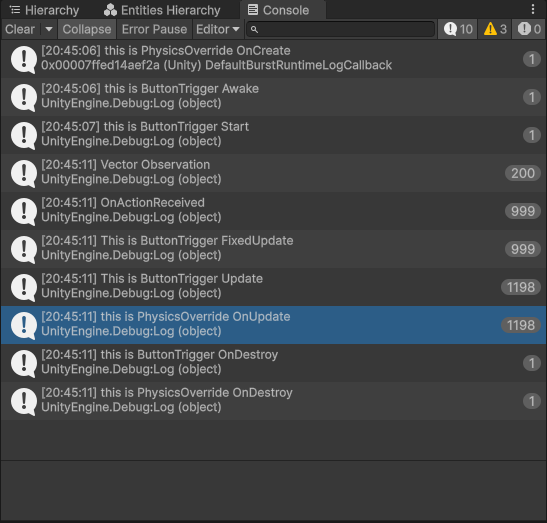
查询文档发现,官方提供的pythonAPI中time-scale能更改untiy内的时间倍率。查看ml-agents源码发现默认20。若在terminal内强制更改time-scale,OnActionReceived的执行次数将回归正常。

更进一步阅读源码和profiler,发现MonoBehaviour与DOTS的更新是分成两块分别更新的。例如:MonoBehaviour分别先后执行FixedUpdate和PhysicsSimulate,重复十次,然后DOTS再执行十次Update。
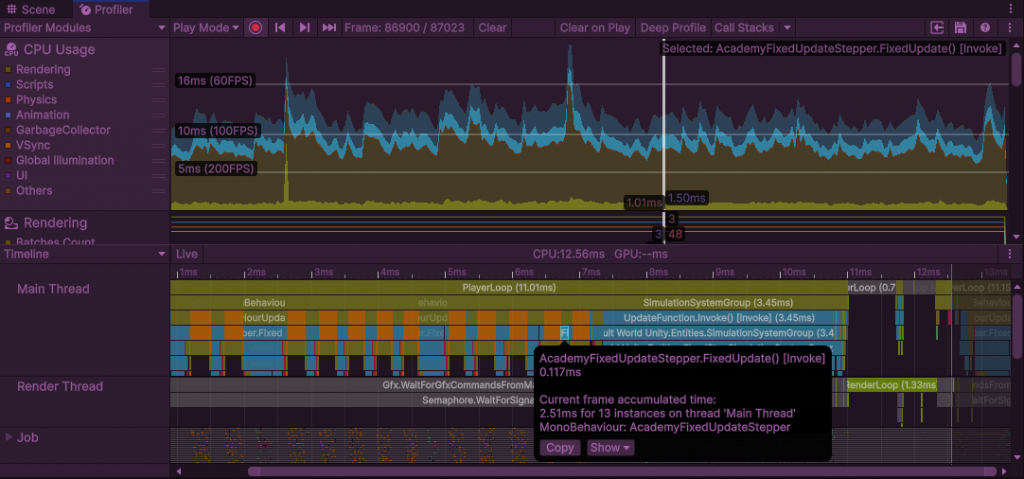
所以如果要正确将ML-Agents融入DOTS,应该在DOTS内完成Academy的工作。
经一下午阅读源码和文档,大概总结出Academy和Agent的关系:
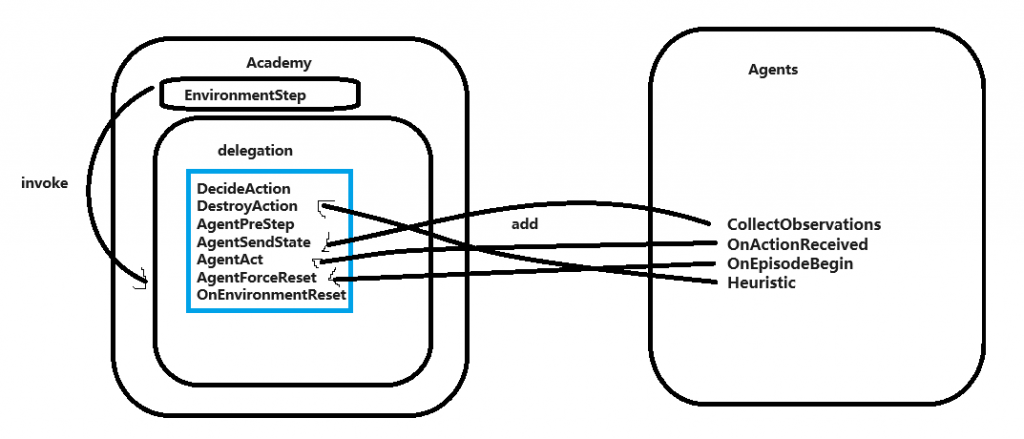
若要完美结合ML-Agents和DOTS,应该将Academy和Agents都移至进DOTS内。因这次项目为验证性项目,保存原有结构,通过Agents再加一层与DOTS交流。Actions传入DOTS,进行物理模拟。DOTS将Observation传进Agents,存入SensorBuffer内。最后在DOTS内执行Academy的EnvironmentStep。
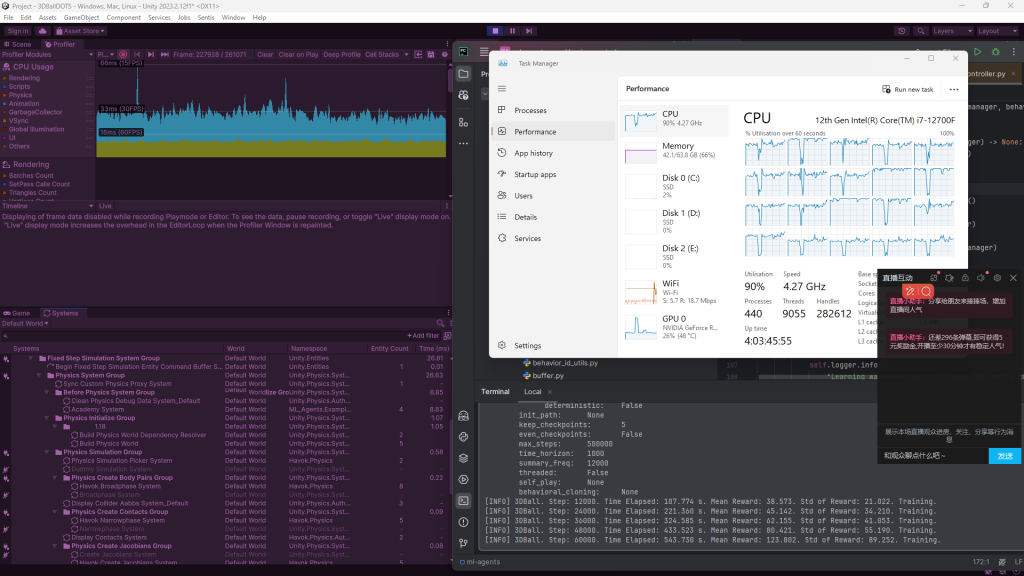
完成浅层的联通后,使用相同的config开启训练端,unity能与python端交流,能产生明显的reward梯度。
DOTS与Mono最明显的区别是效率方面。DOTS深度融合JobSystem,且数据合理规划,能更高效的轮询,批量处理。Mono虽能使用JobSystem,但本身基于GameForObject,面向对象,数据在内存上散乱分布。
比较直观的对比是本地模型情况下,仅使用一个agent,相同时间倍率TimeScale的帧数。
DOTS的帧数稳定在60,当时间倍率从1增到100。Mono部分使用官方示例,当倍率为20时略高于60,当倍率为50时倍率略高于30。DOTS部分除物理部分没使用JobSystem。
后续重构将更进一步融合ML-Agents,并增加Observations和Actions的规模与复杂度。
这几日将联系队内寻人合作,负责日后RMAI的人工智能算法。